秀丸 Archive
CSVファイルなどで、特定の行末改行のみ削除したいとき・・・(秀丸)
- 2010-05-01 (土)
- 秀丸
たとえば、「○○"\n」はそのままにしたいが、
DB内で文字列がそもそも改行されていて、
CSVをテキストエディタで開いて、
-----------
「○○\n
●●●\n
○○○"」
-----------
となっているのを、
-----------
「○○●●●○○○"」にしたいとき・・・
-----------
(※\nは、改行です)
(そもそもsql出力時に調整できるんじゃないかとも思いつつ・・・)
正規表現の置き換えで、
「文末が『"\n』となっているのは、そのままで、それ以外の改行は削除」
という指令をするのですが、それを書くと(秀丸を使っています)
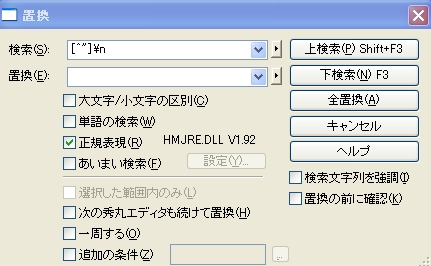
検索に
------------------
[^"]\n
・・・文末が「"改行」以外の「改行」を検索
------------------
と入力し、
置換は「(空)」
正規表現□にチェックを入れて、
「全置換」で成功。
===================
追記・・・やっぱりCSVを出すタイミングで改行コードを削除する方針に変更・・・。
検索すると
replace(フィールド名, "chr(10)", "")
という記述があったんですが、試してみると、
「CHR does not exist」とのこと。
どうやらOracleの文法らしく、mysql(ver5.01)では使えないらしい・・・。
調べまわった挙句・・・
replace(フィールド名, "\r\n", "")
でうまくいった・・・。
(参照)http://www.mysql.gr.jp/mysqlml/mysql/msg/6394
と、思ったらそうでもなかった・・・
「SQL Serverですと「chr」ではなく「char」」という記述も・・・。
(参照)http://www.atmarkit.co.jp/bbs/phpBB/viewtopic.php?topic=25515&forum=26&5
replace(フィールド名, "char(10)", "")
replace(フィールド名, "char(13)", "")
・・・って結局何をどうやってもうまくいかない・・・。
replace(replace(フィールド名, CHAR(10), ''),CHAR(13),'')
で成功!!
めちゃめちゃ時間かかった。複数の改行コードが混じっていたってことなんでしょうね。
「含まれる改行コードがCr+Lfだったり、Lfだけだったりする場合は、二重にして下さい」と記述がございました。